JDBC
¿Qué es
JDBC?
Una de las
desventajas principales de la versión 1.0.2 de Java era que no tenía soporte
alguno para el acceso a bases de datos. Esto limitó la utilidad de Java en el
campo de los negocios. Sin embargo, a partir de la versión 1.1 del JDK, Java
proporciona un soporte completo para bases de datos por medio de JDBC (Java
Database Connectivity). JavaSoft, la subsidiaria de Sun Microsystems referente
a Java, introdujo JDBC el cual permite que los programas Java se conecten a
cualquier base de datos utilizando diversos controladores (conocidos también
como drivers) y un conjunto de objetos y métodos de la API (Interfaz de
Programación de Aplicaciones) de Java.
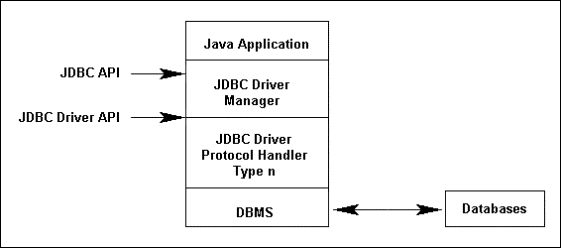
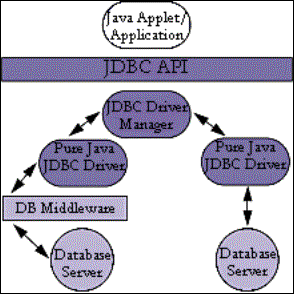
a. Arquitectura
Como se
observa en la figura siguiente, una aplicación front-end utiliza la API de Java
para interactuar con el Driver Manager JDBC. El Driver Manager JDBC utiliza la
API de Driver JDBC para cargar el driver apropiado de JDBC. Los drivers JDBC,
los cuales están disponibles por los proveedores de las diferentes bases de datos
del mercado, se comunican con la capa subyacente del DBMS (Database Manager
System, Sistema Manejador de Bases de Datos).
b. Beneficios
Hasta antes
de la API JDBC, la única forma de acceso a bases de datos desde el Web fue a
través de los programas CGI (Common Gateway Interface). JDBC es mucho más
rápido que los scripts CGI. El uso de CGI por lo regular requiere que se
invoque a otro programa (la librería cliente del manejador de la base de datos)
que tiene que ser ejecutado por la computadora en donde se encuentra la
aplicación CGI. Este programa intermedio realiza el acceso a la base de datos,
procesa los datos y los envía en un flujo al programa que realiza la llamada.
Esto requiere de varios niveles de procesamiento lo que a su vez incrementa el
tiempo de espera así como también propicia que aparezcan más errores.
Invocar un
script CGI implica en realidad ejecutar un nuevo script, por lo regular a
través de un servidor Web, mientras que la ejecución de una instrucción SQL a
través de JDBC en la base de datos requiere sólo de cierto tipo de servidor que
pase los comandos SQL a través de la base de datos. Esto abrevia en forma muy
notable el tiempo que se necesita para ejecutar las instrucciones de SQL.
Mientras que el script CGI debe invocar a la librería cliente para conectarse a
la base de datos y procesar los resultados, la solución JDBC permite que el
programa Java tenga la conexión a la base de datos para, de esa manera, manejar
todo el procesamiento.
Por otro lado, podemos comparar JDBC contra ODBC.
ODBC (Open Database Connectivity) es el estándar de Microsoft para la conexión
a bases de datos. En principio, ODBC está limitado a que el cliente se
encuentre en un sistema Microsoft mientras que el cliente JDBC puede residir en
prácticamente cualquier sistema operativo ya que JDBC está escrito en Java y es
portable a cualquier plataforma.
Por otro lado, la configuración del driver o
controlador para JDBC es más fácil en comparación con el de ODBC.
La API JDBC
define clases Java para representar conexiones a bases de datos, sentencias
SQL, conjuntos de resultados, metadatos de bases de datos, etc. Además permite
al programador escribir en el lenguaje de programación Java y que resultará en
sentencias SQL y procesar los resultados. JDBC es la API primaria para acceso a
bases de datos en el lenguaje de programación Java.
¿Qué
son los drivers y qué hacen?
a. ¿Qué
hace el driver?
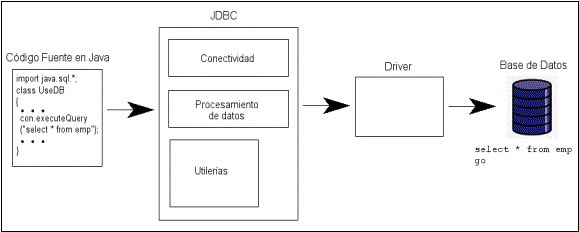
Todos los
programas Java que se conectan a una base de datos vía JDBC, utilizan un driver
o controlador de bases de datos. Es el intermediario entre la capa de negocio y
la capa de base de datos y así mismo funge como el “traductor” de las
sentencias Java a sentencias SQL propias del manejador de bases de datos, como
se puede observar en la siguiente figura:
b.
Tipos
de drivers y arquitecturas
Muchos
motores de bases de datos tienen diferentes tipos de drivers asociados. Los
drivers JDBC caen en una de las siguientes cuatro categorías:
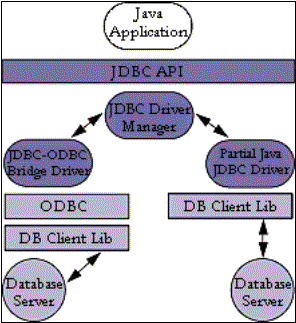
Driver tipo 1: El
bridge JDBC-ODBC (JDBC-ODBC bridge) provee accesos JDBC vía la mayor parte de los drivers
ODBC. Es importante notar que el código binario de algunos drivers ODBC, y en
muchos casos el código del cliente de la base de datos también, deberá ser
cargado en cada máquina cliente que utiliza este driver, por lo que este tipo
de driver es más apropiado en una red corporativa.
Driver tipo 2: Un
driver basado en tecnología Java parcialmente con API nativo (native-API
partly-Java technology-based driver) convierte las llamadas JDBC en llamadas de la API
del cliente para Oracle, Sybase, Informix, DB2 u otros DBMS (Sistemas
Manejadores de Bases de Datos). Es importante notar que este tipo de driver
requiere que algún código binario sea cargado en cada máquina cliente.
Driver tipo 3: Un
driver basado en tecnología Java totalmente con protocolo de red (net-protocol
all-Java technology-based driver) traslada las llamadas de JDBC en un protocolo de red
independiente del DBMS y dicho protocolo es, entonces, trasladado a un
protocolo DBMS por un servidor. Este servidor de red intermedio (middleware)
está habilitado para conectar sus clientes basados en tecnología Java con
muchas diferentes bases de datos. El protocolo de red específico depende del
proveedor. En general, esta es la alternativa JDBC más flexible ya que los
proveedores de los drivers tienen productos que soportan el acceso a Internet e
Intranets así como requerimientos adicionales de seguridad, acceso a través de
muros de fuego (firewalls), etc. Además, varios proveedores están agregando
drivers JDBC a sus productos middleware de bases de datos existentes (Figura
5-6a).
Driver tipo 4: Un
driver basado en tecnología Java totalmente con protocolo nativo
(native-protocol all-Java technology-based driver) convierte las llamadas JDBC a un
protocolo de red utilizado por el DBMS directamente. Esto permite una llamada
directa de la máquina cliente al servidor DBMS y es una solución práctica para
el acceso a Intranet. Debido a que los vendedores de bases de datos son
proveedores de estos protocolos, ellos mismos son la principal fuente de este
estilo de driver por lo que todavía está en desarrollo.
c. Cómo
registrar el driver
Para continuar con la portabilidad de Java y de JDBC,
los drivers son clases Java que vienen empaquetadas en un archivo ZIP o JAR,
eso depende del fabricante del driver. En JDBC, para cargar o registrar el
driver, simplemente se siguen los siguientes pasos:
- Se agrega a la
variable CLASSPATH el archivo que contiene las clases del driver (con su
ruta de directorios). Una alternativa a este paso es agregar el archivo
ZIP o JAR al directorio jre\lib\ext que se encuentra en el directorio raíz del JDK
Standard Edition.
- Se hace uso del
método estático forName() de la clase Class del paquete java.lang:
Class.forName(“nombre_de_la_clase_del_driver”);
Por ejemplo, para cargar el
driver propio de Sybase es:
Class.forName("com.sybase.jdbc2.jdbc.SybDriver");
y para cargar el driver de Oracle es:
Class.forName("oracle.jdbc.driver.OracleDriver");
Y así como se
ejemplificó para estos dos manejadores de bases de datos, así se realiza para los
demás. Posteriormente, ya en el código, se requiere realizar la conexión a la
base de datos.
Manejo
de conexiones (creación, acceso a datos, transacciones y destrucción)
Para crear y
establecer una conexión a una base de datos desde JDBC, se requiere utilizar el
método estático getConnection() de la clase DriverManager del paquete java.sql:
Connection con =
DriverManager.getConnection(String url, String user, String
password);
donde el
primer argumento es un String que le indica a JDBC el sistema en donde reside
la base de datos. La sintacis estándar del URL de JDBC es de la siguiente
manera:
jdbc:subprotocolo:servidor.dominio:puerto{/|:}base_de_datos
Importante: en el campo servidor.dominio se puede
colocar el nombre del sistema o su dirección IP asociada. Las llaves indican
que en algunos manejadores, después del número de puerto sigue un diagonal (/) o los dos
puntos (:) para después indicar el nombre de la base de datos.
En este caso, el texto en negrillas indica que se deben
colocar los valores específicos a la base de datos. Este URL cambia de un
manejador de bases de datos a otro y en la documentación específica de cada
driver se explican los valores. El segundo y el tercer argumento indican el
login y el password del usuario que tiene acceso a la base de datos indicada en
el URL. Por ejemplo, si se tiene una base de datos Sybase llamada pubs en el sistema
odin.fi-b.unam.mx en el puerto 1521 y cuyo
usuario tiene el login dba y el password sql, entonces la
sentencia de conexión es:
con = DriverManager.getConnection(
"jdbc:sybase:Tds:odin.fi-b.unam.mx:1521/pubs",
"dba","sql");
Si se tuvieran
los mismos datos pero para conectarse a una base de datos Oracle, la sentencia
sería:
con = DriverManager.getConnection(
"jdbc:oracle:thin:@odin.fi-b.unam.mx:1521:pubs",
"dba","sql");
Importante: Para la conexión a Oracle,
el campo servidor.dominio va antecedido por una
arroba (@) y es propio de la sintaxis de Oracle.
Posteriormente
a la creación de la conexión se debe tomar en cuenta si la conexión va a involucrar
transacciones. En el caso de JDBC, al final de cada sentencia SQL se realiza el
commit de manera automática y predeterminada. Por ello, si vamos a manejar
transacciones, podemos habilitar o deshabilitar la opción de autocommit. Para ello,
sobre el objeto Connection recientemente creado,
invocamos al método setAutoCommit() pasando un argumento tipo boolean. Si el
boolean es true, entonces el autocommit está activo
(esta es la opción por defecto de JDBC) mientras que si es false, entonces se
ha desactivado el autocommit y siendo así, se debe realizar el commit
de manera manual al final de la transacción.
con.setAutoCommit(
false );
Posteriormente,
se tienen 3 opciones: crear un objeto de tipo Statement, un objeto de
tipo PreparedStatement o un objeto de tipo CallableStatement.
Si se está
utilizando una transacción, se debe realizar ya sea un commit (para
confirmar las acciones hechas en las tablas) o un rollback (para
deshacer los cambios). Ambas acciones son sobre la referencia de tipo Connection:
con.commit();
o bien,
con.rollback();
Es
recomendable que siempre se cierre la conexión una vez finalizada la ejecución
de la(s) sentencia(s) SQL, con el método close():
con.close();
API de
JDBC
a. Diferentes
tipos de Statements
El objeto Statement
El objeto de
tipo Statement se utiliza para crear sentencias SQL estáticas y
regresar el resultado que éstas producen. Por lo general, el objeto Statement se utiliza
para la ejecución de sentencias SELECT y en ese caso, se invoca al método executeQuery() el cual
regresa un objeto ResultSet que contiene los registros resultantes de la
consulta:
Statement
stm = con.createStatement();
ResultSet
res =
stm.executeQuery(“select
cve_emp,nom_emp from emp”);
También se
utiliza para realizar sentencias INSERT, UPDATE y DELETE y en ese caso, se
utiliza el método executeUpdate() llevando como argumento el
String con la sentencia SQL:
Statement
stm = con.createStatement();
int res =
stm.executeUpdate(“insert into emp
values(‘123’,‘Carlos
Roman’)”);
El objeto PreparedStatement
El objeto de
tipo PreparedStatement se utiliza para ejecutar sentencias SQL
precompiladas (o dinámicas en cuanto a los valores de los parámetros en la
condición de la sentencia SQL). Por lo general, PreparedStatement se utiliza
para la ejecución de sentencias INSERT, DELETE y UPDATE ya que éstas últimas
requieren condicionantes por lo que se crea el String con la
sentencia SQL desde la obtención del objeto PreparedStatement. Para
establecer el valor de una condicionante, se utilizan los diversos métodos setXXX() donde XXX representa a
cada uno de los diversos tipos de datos que existen en Java (int, byte, float, double, String, etc) y
posteriormente se invoca al método executeUpdate() el cual
regresa un valor int que indica el número de registros afectados
por la sentencia (ya sea INSERT, UPDATE o DELETE). Por ejemplo, utilizando el
objeto PreparedStatement:
PreparedStatement
pstmt =
con.prepareStatement(“update emp
set nom_emp=?
where cve_emp=?)”);
pstmt.setString(1,“Carlos
Roman”);
pstmt.setInt(2,123);
int res =
pstmt.executeUpdate();
Se observa que
JDBC sustituye los signos de interrogación (?) por los valores según el orden
establecido por el primer argumento del método setXXX(). También
existe la posibilidad de crear una sentencia SELECT con argumentos asignados
dinámicamente así que PreparedStatement también tiene el método executeQuery() que regresa
un objeto ResultSet, con los registros resultantes:
PreparedStatement
pstmt =
con.prepareStatement(“select
cve_emp,nom_emp from emp
where cve_emp=?)”);
pstmt.setInt(1,123);
ResultSet
res = pstmt.executeQuery();
El objeto CallableStatement
El objeto de
tipo CallableStatement se utiliza para ejecutar procedimientos almacenados
(stored procedures) SQL. La API de JDBC provee una sintaxis para que
todos los procedimientos almacenados sean llamados de la misma manera en los
diferentes sistemas manejadores de bases de datos. Dicha sintaxis provee una
manera que incluye un parámetro de resultado y otra manera que no incluye dicho
parámetro. Si el parámetro es utilizado, debe ser registrado como un parámetro
OUT. Los parámetros restantes pueden ser utilizados para entrada, salida o
ambos. Los parámetros son referenciados a través de un número secuencial,
empezando por 1. Las sintaxis son:
{?= call <nombre_del_procedimiento_almacenado>[<arg1>,<arg2>, ...]}{call < nombre_del_procedimiento_almacenado >[<arg1>,<arg2>, ...]}
Los valores de
los parámetros IN (de entrada) están establecidos por los métodos setXXX() heredados de PreparedStatement. Los tipos de
todos los parámetros OUT (de salida) deben ser registrados ejecutando el
procedimiento almacenado, sus valores son recuperados después de la ejecución a
través de los métodos getXXX() que provee CallableStatement.
Un objeto CallableStatement también puede
regresar un objeto ResultSet o múltiples objetos ResultSet. En este
último caso, los múltiples objetos ResultSet son manejados por métodos
heredados de Statement.
b. Diferentes
tipos de ResultSets
El objeto ResultSet
Este objeto
representa los datos resultantes de la ejecución de un query a la base de
datos. Este objeto está muy relacionado a la sentencia SELECT ya que es la
única que permite registros como respuesta, además de los procedimientos
almacenados.
Este objeto
tiene un cursor el cual, de entrada está antes del primer registro resultante
(si hay registros resultantes) y conforme se navega por los registros, el ResultSet mantiene el
cursor en el registro actual. De manera predeterminada un ResultSet no es
actualizable y su cursor se mueve solamente hacia delante (TYPE_FORWARD_ONLY). Es posible
crear objetos ResultSet actualizables así como también que sus cursores puedan
desplazarse no sólo hacia delante (con esta característica, se dice que el
ResultSet es scrollable):
Statement stmt = con.createStatement( ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_UPDATABLE);ResultSet rs = stmt.executeQuery("SELECT a, b FROM TABLE2");
La interfaz
ResultSet provee los metodos getXXX() donde XXX representan
los diversos tipos de datos con los que cuenta Java (boolean, long, int, etc.) para
regresar los datos de las columnas del resultado de la sentencia SQL. El
argumento que los métodos getXXX() requieren puede ser el índice que la columna
ocupa en la sentencia SELECT o el nombre de la columna (esta última opción es
de caso no-sensitivo).
Los diversos
métodos getXXX() de un objeto ResultSet son los siguientes (recuerde que deben llevar
como argumento ya sea el índice o el nombre de la columna y algunos métodos
están sobrecargados para recibir más argumentos. Para un mayor detalle,
consultar la API de la interfaz ResultSet):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Antes de la
versión 2.0 de JDBC, los ResultSet eran de sólo lectura y solamente se podían
recorrer en una sola dirección, hacia delante y cada elemento era obtenido
llamando al método next(). A partir de JDBC 2.0 se introducen ResultSet cuyos
valores pueden ser leídos (hacia atrás y hacia delante) y actualizados si estas
acciones están soportadas por el manejador de bases de datos. Las
actualizaciones se realizan sin invocar al método executeUpdate() y son
realizadas utilizando llamadas de JDBC y no sentencias SQL, mejorando la
portabilidad del código.
Tanto
Statement como PreparedStatements cuentan ahora con un constructor que reciben
el tipo de navegación y el tipo de actualización del ResultSet. El tipo de
navegación puede ser uno de los siguientes:
- ResultSet.TYPE_FORWARD_ONLY
Esta es la conducta por defecto en JDBC 1.0. La aplicación sólo puede invocar al método next() del ResultSet. - ResultSet.SCROLL_SENSITIVE
El ResultSet es completamente navegable y sus actualizaciones se reflejan en ese mismo objeto ResultSet. - ResultSet.SCROLL_INSENSITIVE
El ResultSet es completamente navegable, pero las actualizaciones son solamente visibles hasta que este objeto ResultSet es cerrado, por lo que se necesitará crear un nuevo objeto ResultSet para observar los resultados.
El tipo de
actualización puede ser uno de los dos siguientes valores:
ResultSet.CONCUR_READ_ONLY
El ResultSet es de solo lectura.ResultSet.CONCUR_UPDATABLE
El ResultSet si es actualizable.
Se puede
verificar si la base de datos soporta estos tipos llamando al método con.getMetaData().supportsResultSetConcurrency() como se
muestra a continuación:
Connection con = getConnection(); if(con.getMetaData().supportsResultSetConcurrency( ResultSet.SCROLL_INSENSITIVE, ResultSet.CONCUR_UPDATABLE)) { PreparedStatement pstmt = con.prepareStatement( "select password, emailaddress, creditcard, balance from registration where theuser = ?", ResultSet.SCROLL_INSENSITIVE, ResultSet.CONCUR_UPDATABLE); }
El objeto ResultSetMetaData
El objeto ResultSetMetaData es utilizado
para obtener información de los datos y propiedades de las columnas contenidas
como resultado en un objeto ResultSet. En pocas palabras contiene la metadata
(los datos de los datos) como pueden ser: número de columnas, nombres de
columnas, tipos de datos de las columnas, etc.
El siguiente
fragmento de código crea el objeto ResultSet rs, crea el objeto rsmd de tipo ResultSetMetaData y lo utiliza
para encontrar cuántas columnas tiene el objeto rs y ver si la
primera columna puede ser utilizada en una cláusula WHERE:
ResultSet rs = stmt.executeQuery("SELECT a, b, c FROM TABLE2"); ResultSetMetaData rsmd = rs.getMetaData(); int numberOfColumns = rsmd.getColumnCount(); boolean b = rsmd.isSearchable(1);